
單細胞蛋白組旨在通過高分辨率的質譜技術對單個細胞內的蛋白質進行全面解析。這一技術突破了傳統整體蛋白質組學的局限性,能夠深入揭示細胞間的異質性及其在復雜生物系統中的作用。每個細胞都是一個獨立的微型生物工廠,內部蛋白質的種類、含量及修飾狀態直接決定了細胞的功能與狀態。然而,由于細胞間的高度異質性,即使在同一個組織中,細胞之間的功能和響應機制也可能存在顯著差異。傳統的蛋白質組學方法往往只能提供整體平均信息,無法揭示單個細胞層面的獨特特征。而單細胞蛋白組技術能夠將組織解離成單個細胞,并對每個細胞進行獨立的蛋白組分析,從而揭示細胞間的差異性及其生物學意義。這對于腫瘤微環境、免疫細胞功能、發育生物學及藥物響應機制等領域具有重要的應用價值。例如,在腫瘤研究中,不同細胞亞群的特定蛋白表達譜往往與腫瘤的侵襲性、轉移能力和治療耐藥性密切相關。通過單細胞蛋白組分析,我們不僅可以鑒定關鍵的蛋白分子,還能夠構建細胞間相互作用網絡,揭示細胞行為背后的分子機制。此外,單細胞蛋白組還能夠捕捉到細胞在不同時間點的動態變化,為揭示細胞分化、發育和疾病進展的過程提供強有力的工具。百泰派克生物科技使用全流程集成自動化的單細胞分選平臺cellenONE分選得到的單細胞使用基本無損的蛋白前處理方法酶切,得到的肽段使用最新的,高靈敏度的Thermo Orbitrap Astral設備上機檢測,保證數據質量。
一、項目概述
1、項目信息

表1. 項目信息表

表2. 樣本信息表
注:實驗室收到樣本后對樣本進行編號,后均以樣本編號代替樣本名稱。
二、實驗說明
1、實驗流程總覽
本實驗對客戶提供的樣品進行單細胞蛋白組分析,主要實驗流程如下:

圖1
2、實驗材料與設備
(1)試劑耗材
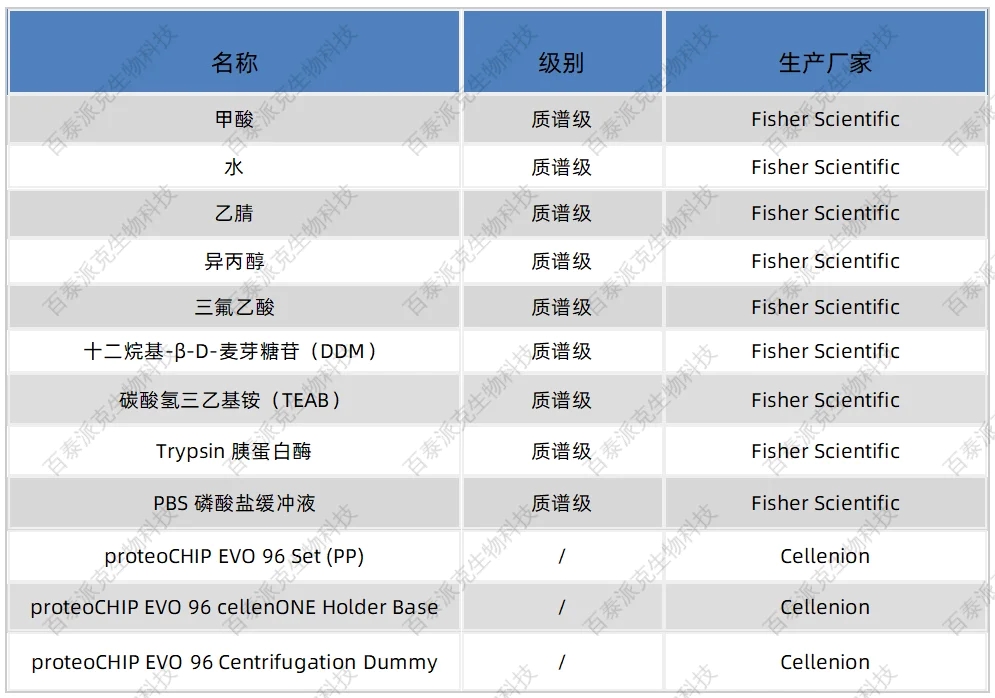
表3
(2)儀器設備

表4
3、實驗方法
(1)樣品處理
① 收集細胞:100~200 細胞 /µL。
② 鋪板:使用cellenOne 每孔加入 1µL 的 master mix buffer。
③ Mapping:cellenOne 自動進樣針吸取 5~10µL 細胞溶液,進行細胞Mapping,判斷細胞形態、密度、直徑是否符合要求,獲取 Mapping 報告。
④ 分選:根據Mapping結果,設置細胞直徑范圍和Elongation factor(通常為 1.5~1.8),進行細胞分選,最后獲取分選結果。
⑤ 補液:細胞分選完成后,使用cellenOne每孔加入 500nL master mix buffer。
⑥ 酶切:設置cellenOne樣品盤溫度為50°C,濕度85%,恒溫恒濕下,進行酶切反應1h,并開啟全程自動循環補水500nL/孔,反應結束后,樣品盤溫度冷卻至 20°C。
⑦ 淬滅:每孔手動加入 3.5µL 0.1%TFA/1% DMSO。
⑧ 封板和上樣:96/384 孔板蓋子封板后置于 Vanquish Neo 中,上樣 4µL,進行數據采集。
(2)LC-MS/MS檢測
① 液相色譜條件
● 流動相A:0.1% 甲酸水。
● 流動相B:80% 乙腈 /0.1% 甲酸水。
● 流速:0.2μL/min。
● 色譜柱:Ionopticks Aurora Elite 15cm x 75 μm ID, 1.7 μm C18 (包含 emitter),柱溫60℃。
● AS樣品盤溫度:7°C。
● 洗針液:強洗:80%乙腈/0.1%甲酸水;弱洗:0.1%甲酸水。
● 洗針模式:After Draw。
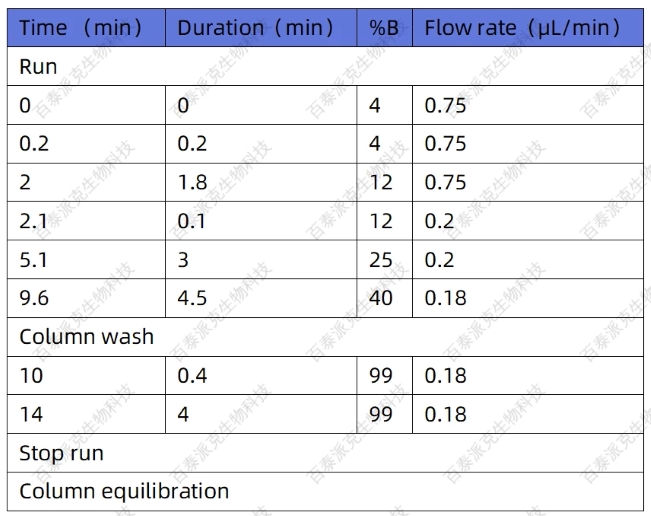
表5
② 質譜條件
● 一級質譜參數:
Resolution:240,000
AGCtarget:500%
MaximumIT:100 ms
Scanrange:400 to 800m/z
● 二級質譜參數:
Scanrange:150 to 2000m/z
AGCtarget:800%
三、數據分析
1、數據分析流程總覽
基于質譜下機數據,使用數據庫搜索軟件進行肽段和蛋白質的鑒定和定量;通過肽段序列長度分布等分析來評估質譜檢測數據的質量;采用降維分群方法對單細胞進行分析,結合差異統計,分析各分群差異蛋白;最后對差異蛋白進行GO、KEGG功能富集等一系列功能分析,探索蛋白在單細胞維度的異質性表達和功能特征。生物信息學分析總體流程如下圖:
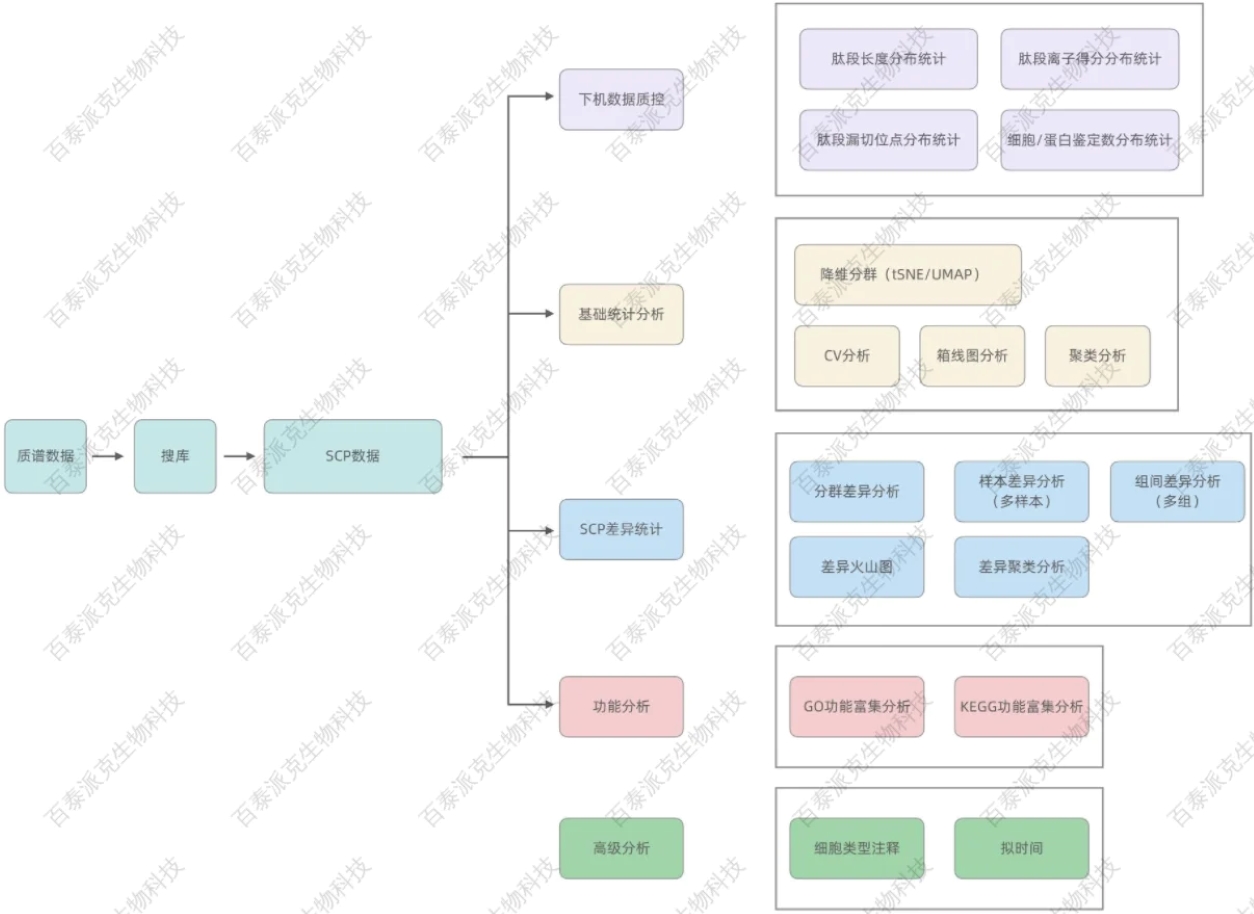
圖2
2、數據庫檢索
質譜原始文件使用DIANN(version) 分別檢索目標蛋白數據庫,檢索參數如下:
(1)固定修飾(Fixed modifications):Carbamidomethyl (C)
(2)可變修飾(Variable modifications):Acetyl (N-term), Oxidation (M)
(3)酶(Enzyme):Trypsin
(4)數據庫(Database):uniprot_Homo sapiens (Human)
(5)遺漏酶切位點(Maximum Missed Cleavages):3
(6) 一級質譜誤差(Peptide Mass Tolerance):20 ppm
(7) 二級質譜誤差(Fragment Mass Tolerance):0.02 Da
3、鑒定結果總覽
基于數據庫檢索結果,我們統計各細胞蛋白/肽段鑒定數目,最終鑒定結果如下:
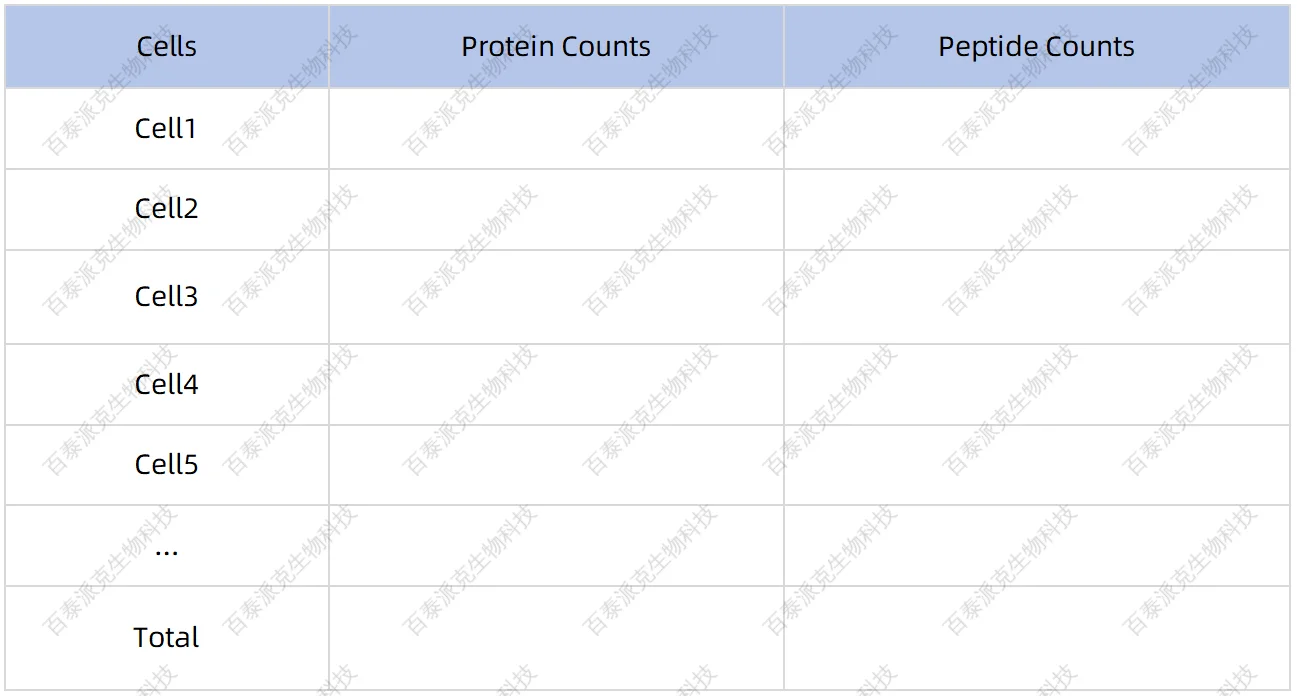
表6. 鑒定結果統計表
注:(1)Protein Counts:蛋白鑒定數;(2)Peptide Counts:肽段鑒定數。
4、數據質控
基于數據庫檢索結果,我們統計肽段長度分布和肽段離子得分分布,對質譜下機數據進行數據質控。
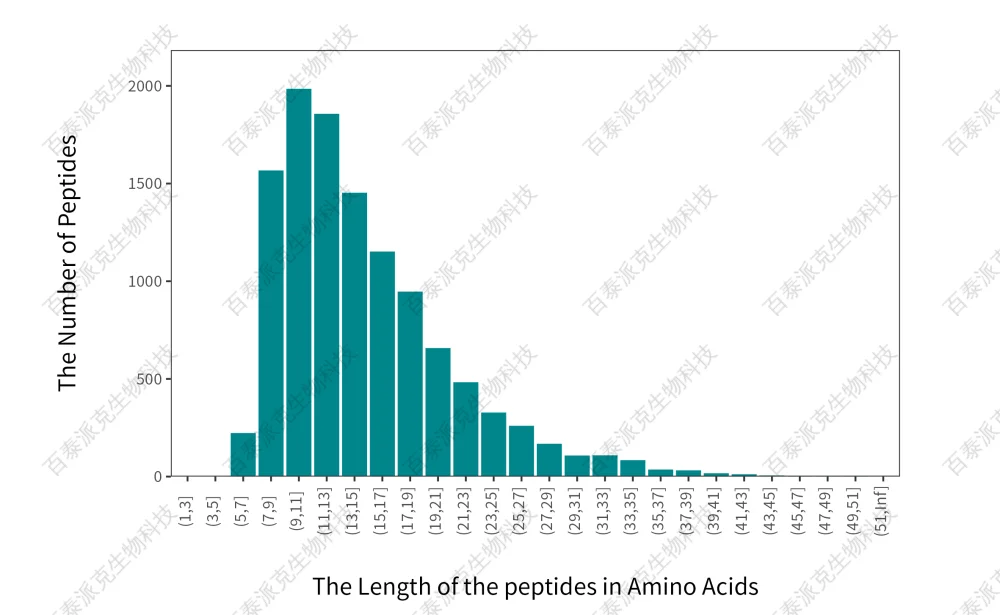
圖3. 肽段長度分布圖
注:橫坐標表示肽段長度分布區間,縱坐標表示區間內肽段數。
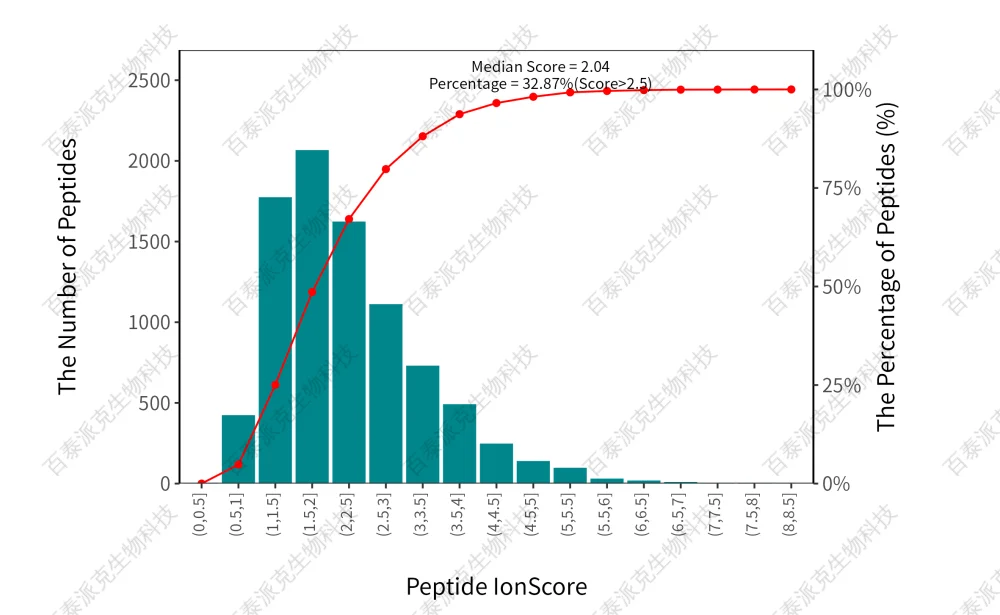
圖4. 肽段離子得分分布圖
注:橫坐標表示肽段離子得分區間,左側縱坐標表示區間內肽段數,右側縱坐標表示累計肽段數分布百分比。
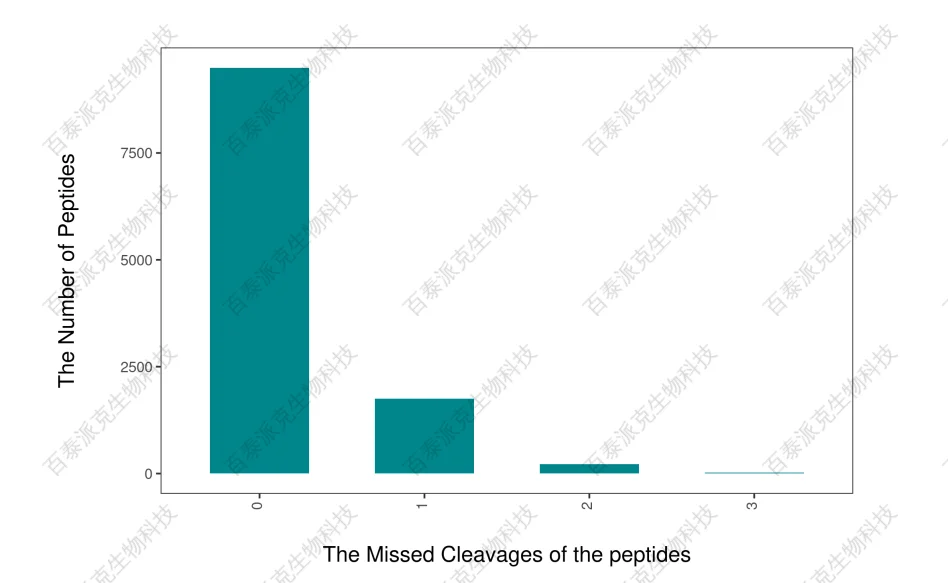
圖5. 肽段漏切位點分布圖
注:橫坐標表示肽段漏切位點數,左側縱坐標表示不同漏切位點對應的肽段數。
5、降維分群
(1)降維分群
降維指采用某種映射方法,將原高維空間中的數據點映射到低維度的空間中。
PCA是最常用的無監督線性降維方法,能將多個指標轉換為少數幾個主成分,這些主成分是原始變量的線性組合,且彼此之間互不相關,其能反映出原始數據的大部分信;tSNE和UMAP則屬于非線性降維算法,也是目前單細胞數據常用的降維可視化方法。
單細胞聚類分群是基于降維之后的數據根據聚類算法對細胞進行分群聚類,并結合tSNE/UMAP降維結果進行展示。
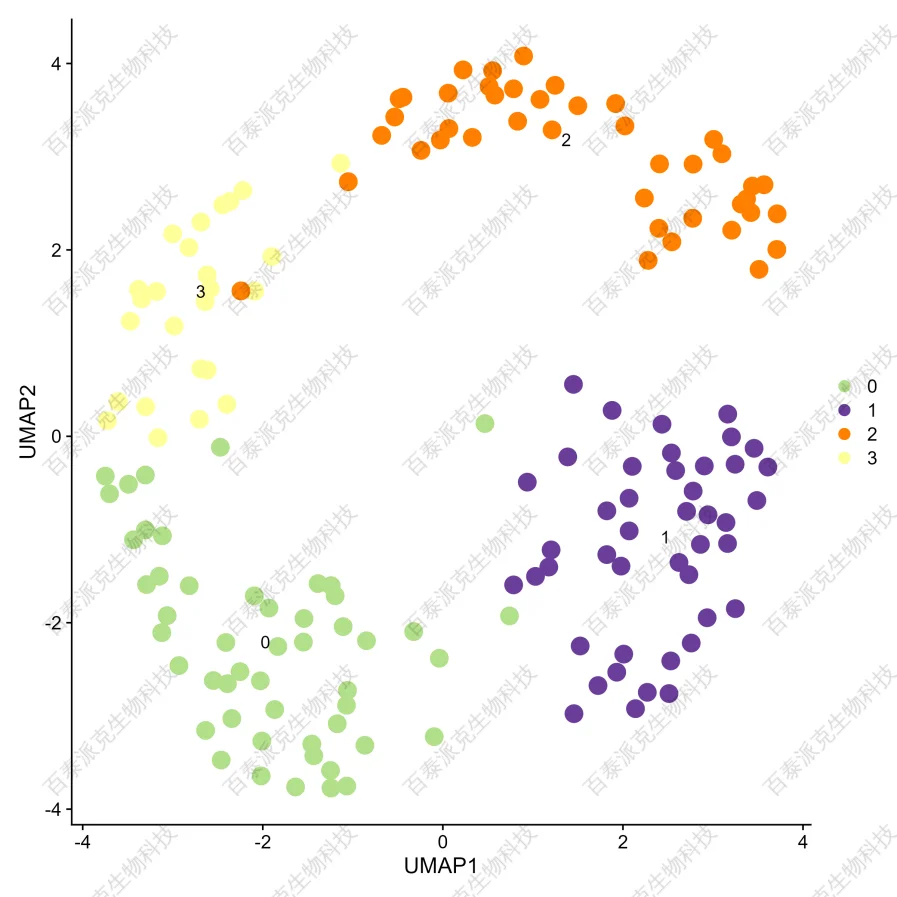
圖6
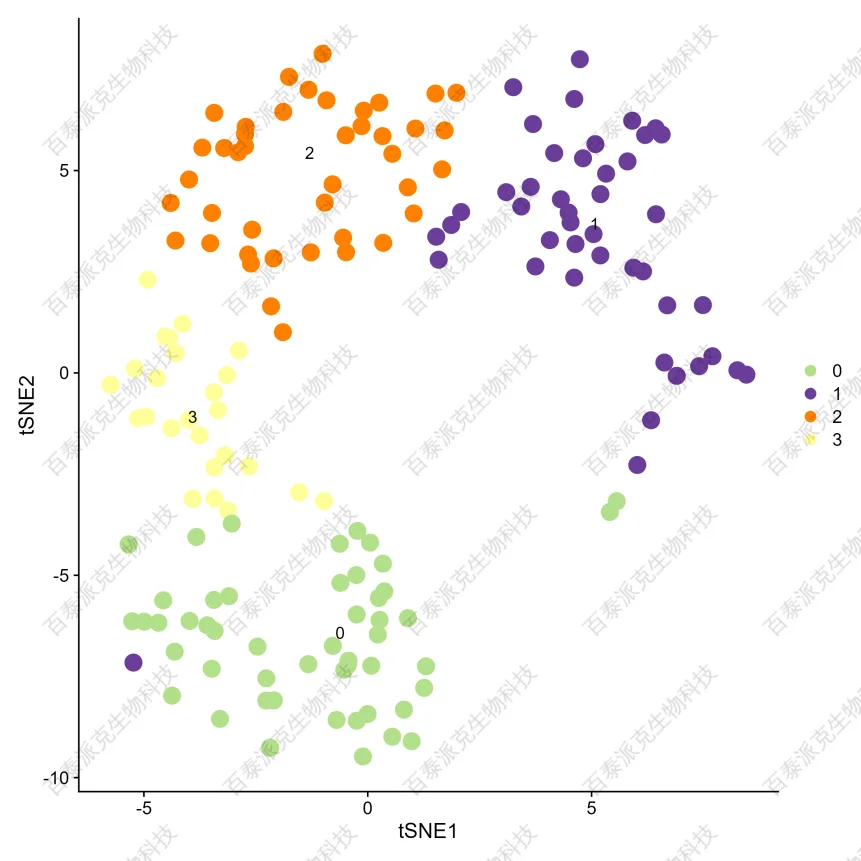
圖7. 單細胞降維分群結果(UMAP/tSNE)
注:以不同顏色標注不同的細胞分群結果。
(2)CV分析
在統計學中,變異系數(CV)是標準差與平均值之比,用于描述數據的變異程度。CV值越小,表示數據越穩定,變異程度越小。統計各Cluster內蛋白定量值CV,并以箱線圖方式進行展示,可以有效評估Cluster內蛋白是否波動,Cluster間是否差異。
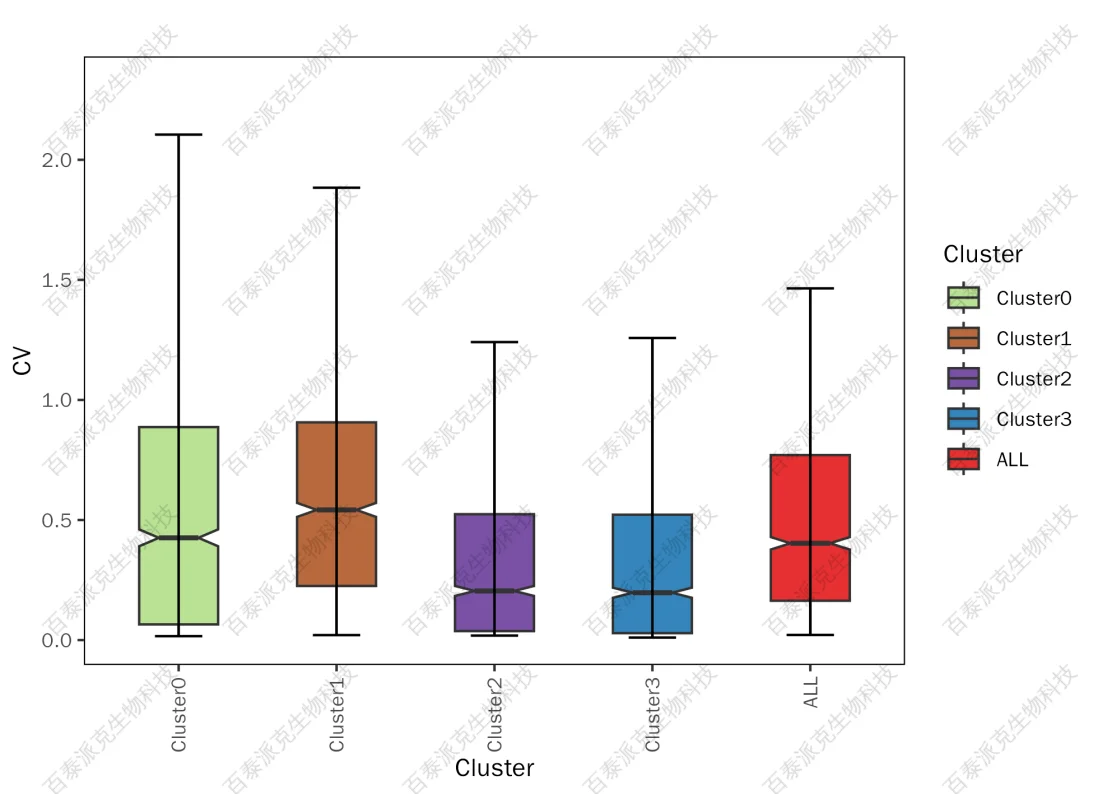
圖8. 各Cluster蛋白豐度CV箱線圖
注:橫坐標表示Cluster,縱坐標表示Cluster內定量值CV的分布區間。
(3)Cluster數據分布
箱線圖是對數據分布的一種常用表示方法,因形狀如箱子而得名。它利用上四分位數、中位數、下四分位數等幾個統計量可以粗略觀察數據是否對稱,分布的離散程度等。
結合分群Cluster結果,統計Cluster內蛋白在各細胞中平均豐度水平。再以箱線圖形式對平均豐度情況進行可視化,可以對不同Cluster內蛋白平均情況進行整體觀察比較。
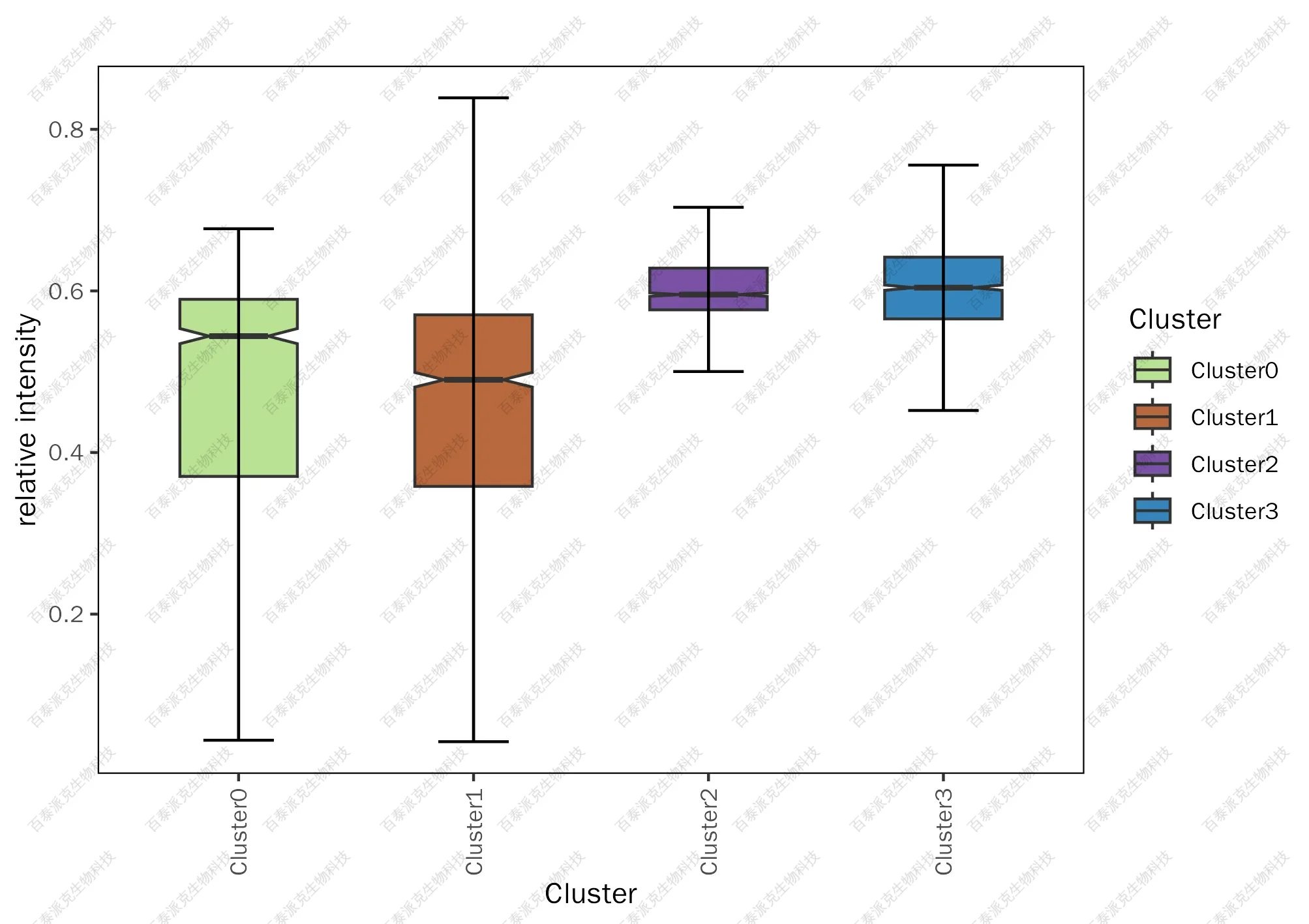
圖9. 各Cluster蛋白平均豐度箱線圖
注:橫坐標表示樣本,縱坐標表示定量值分布區間。
(4)聚類熱圖
基于蛋白在不同細胞內的豐度水平,結合降維分群的信息,以聚類熱圖的形式進行展示,可以對所有Cluster內各細胞蛋白豐度的趨勢進行觀察,也可以對不同Cluster蛋白豐度趨勢進行比較。
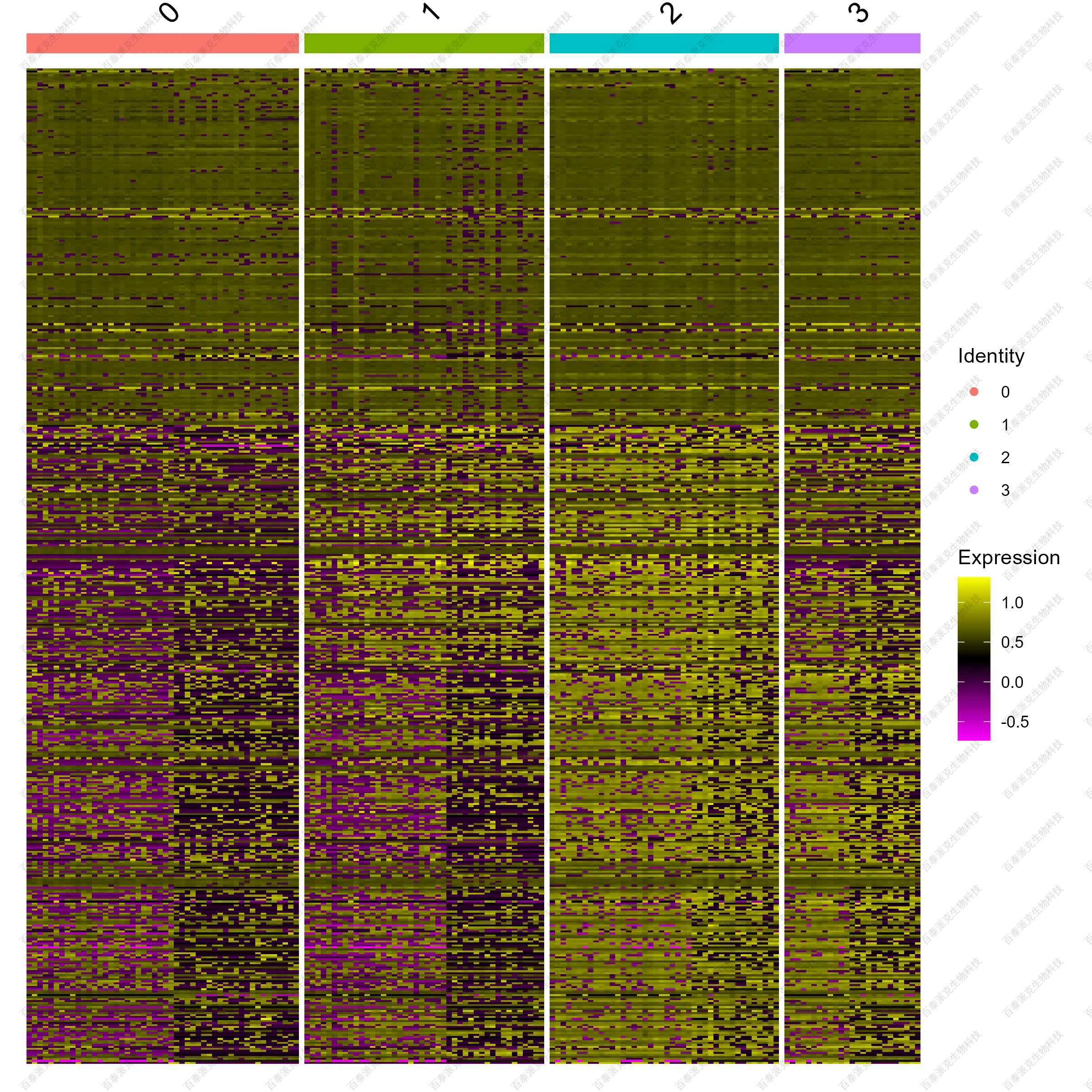
圖10. 單細胞蛋白豐度聚類熱圖
注:橫向表示各蛋白,縱向表示各個細胞,熱圖上方用不同的顏色對Cluster進行注釋;熱圖顏色變化的深淺表示蛋白豐度的高低。
6、差異表達分析
我們利用差異倍率FC (Fold Change) 和t-test的顯著性水平p_value來篩選差異蛋白,篩選標準為:|log2FC|>=1且p_value<0.05。
如提供多樣本,亦可針對樣本間,或樣本分組間,進行差異分析。
(1)差異結果匯總
默認將不同Cluster與其他Cluster分別進行比較,根據差異統計結果,我們將篩選的差異蛋白分為上調表達和下調表達。各差異結果如下:

表7. 差異結果統計表
注:1)Compare:比較組;2)Up:上調表達的差異蛋白數;3)Down:下調表達的差異蛋白數。
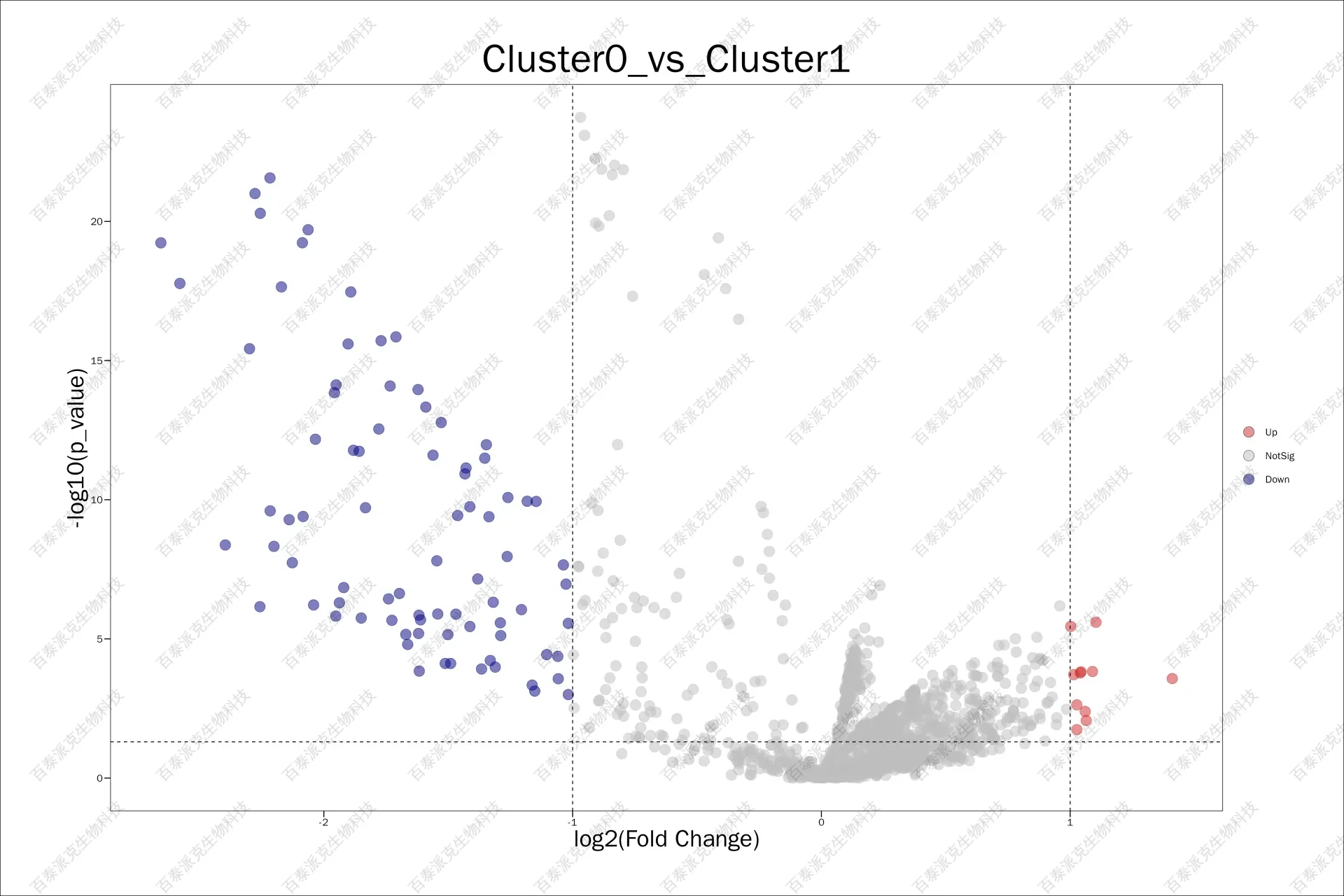
圖11. 差異分析火山圖
注:橫坐標表示log2(Fold Change) ,縱坐標表示差異顯著性。
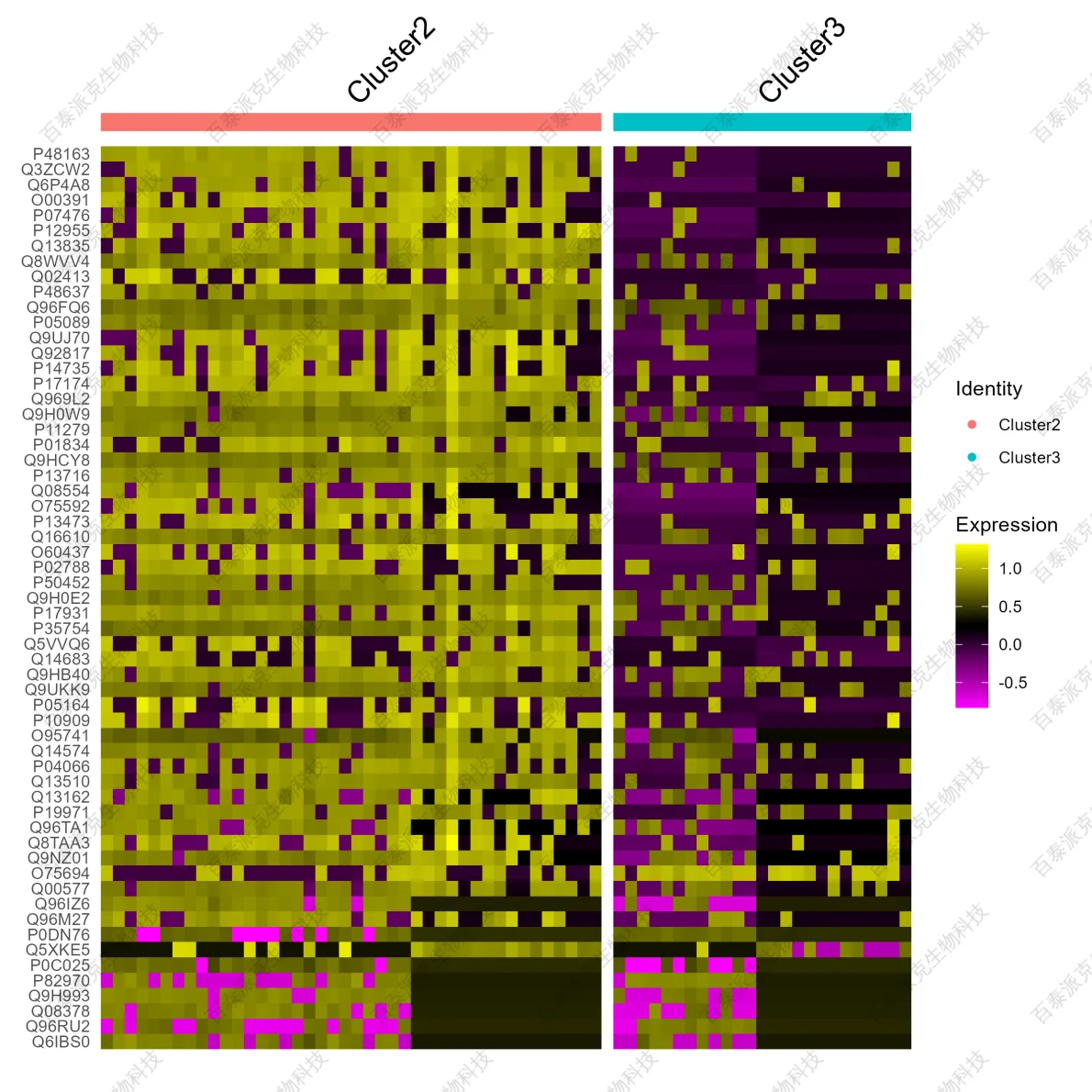
圖12. 差異蛋白聚類熱圖
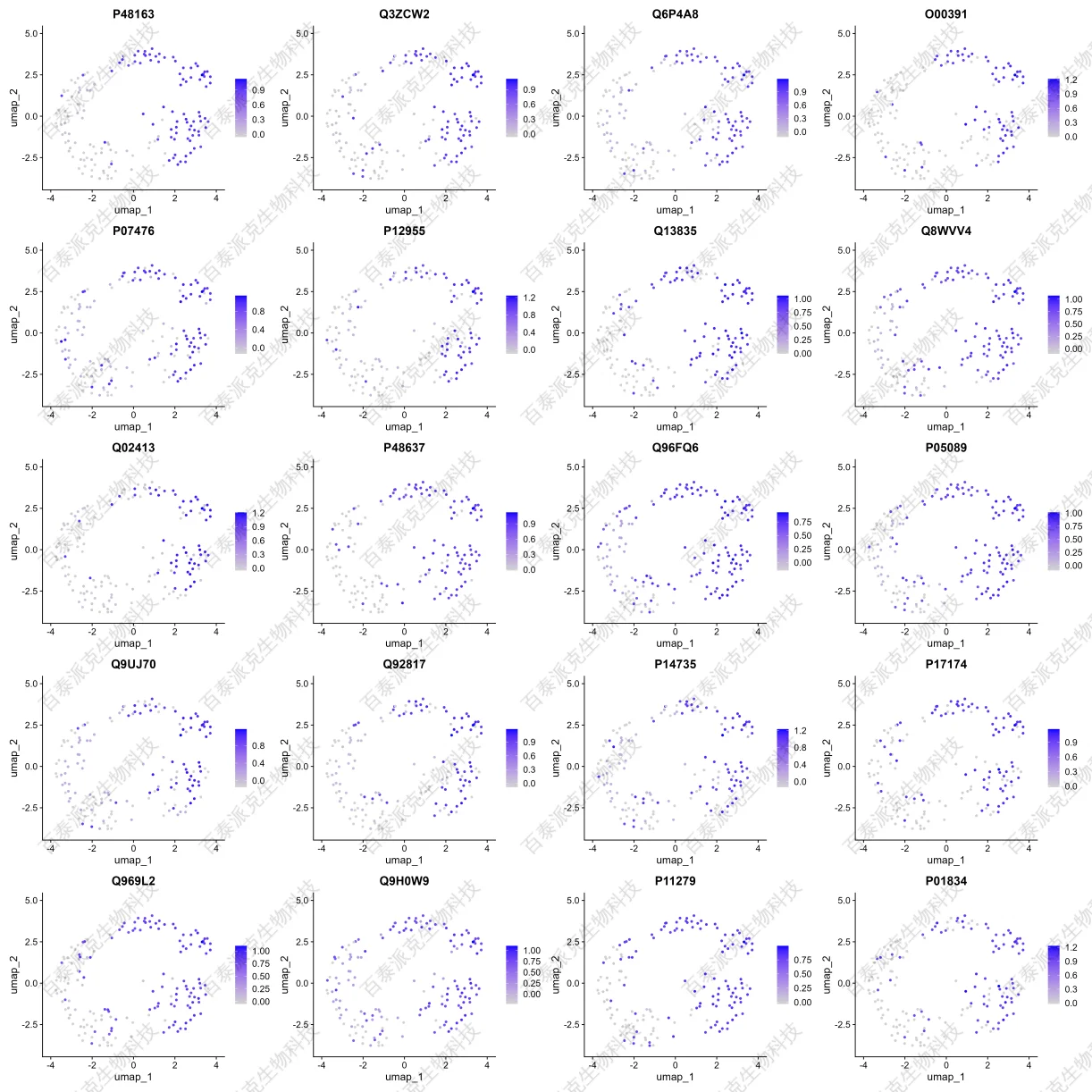
圖13. Top20(p_value)蛋白豐度/降維分布圖
7、功能富集分析
Gene Ontology(簡稱 GO, http://www.geneontology.org/)是基因功能國際標準分類體系。作為基因本體聯合會(Gene Onotology Consortium)所建立的數據庫,它旨在建立一個適用于各種物種的,對基因和蛋白質功能進行限定和描述的,并能隨著研究不斷更新。GO分為分子功能(Molecular Function,描述在分子水平上基因產物的活性元件)、生物過程(Biological Process,表示一個分子活動事件從起始到終止的過程,包括細胞、組織、器官和物種的功能整合)、和細胞組成(Cellular Component,表示細胞或其所處外界環境)三個部分。
KEGG(Kyoto Encyclopedia of Genes and Genomes)是系統分析基因功能、基因組信息的數據庫,包括七大類別:Metabolism,Genetic Information Processing,Environmental Information Processing,Cellular Processes,Organismal Systems,Human Diseases,Drug Development。其中KEGG Pathway數據庫是最重要也是最常用的子數據庫。作為有關Pathway的主要公共數據庫,KEGG提供的整合代謝途徑查詢,包括碳水化合物、核苷、氨基酸等的代謝及有機物的生物降解,不僅涉及了所有可能的代謝途徑,而且還對催化各步反應的酶進行了全面的注解,包含有氨基酸序列、PDB庫的鏈接等等,是進行生物體內代謝分析、代謝網絡研究的強有力工具。
基于GO和KEGG Pathway數據庫的富集分析,常利用超幾何分布算法進行,主要是根據目標基因集合與背景相比,分析目標基因集合與哪些生物學功能/代謝通路顯著相關。在蛋白質組分析中,我們以蛋白為目標基因集進行富集分析,以期闡明實驗中樣本差異在基因功能上的體現。
(1)GO富集分析
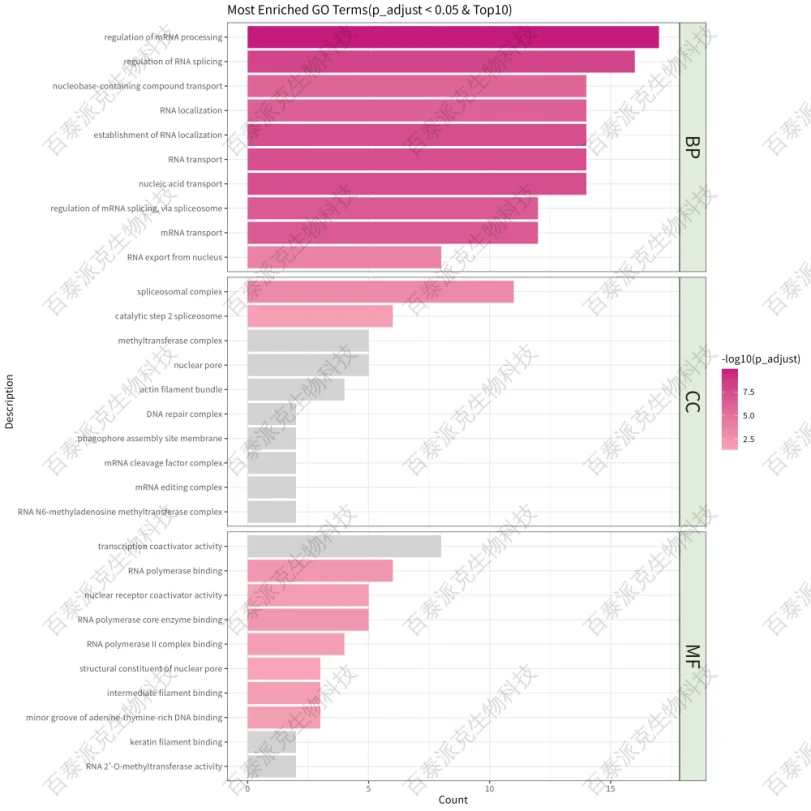
圖14. GO富集柱狀圖
注:橫坐標表示GO Term上注釋到的基因數目,縱坐標表示BP、CC、MF按照p_adjust篩選Top10的GO Term;顏色深淺表示富集的顯著性大小,越顯著越紅;灰色的柱子表示p_adjust ≥0.05的GO Term。
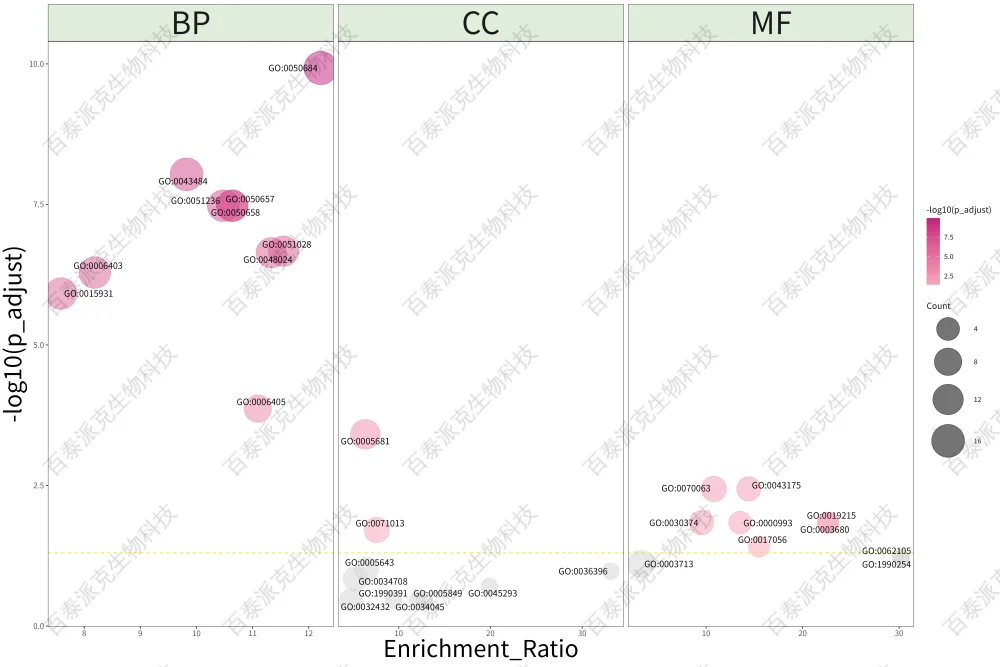
圖15. GO富集泡泡圖
注:橫坐標表示GO Term的Enrichment Ratio,縱坐標表示GO Term的-log10(p_adjust),值越大越顯著;顏色深淺表示富集的顯著性大小,越顯著越紅;橫向黃色虛線以下灰色的圓圈表示p_adjust ≥0.05的GO Term。
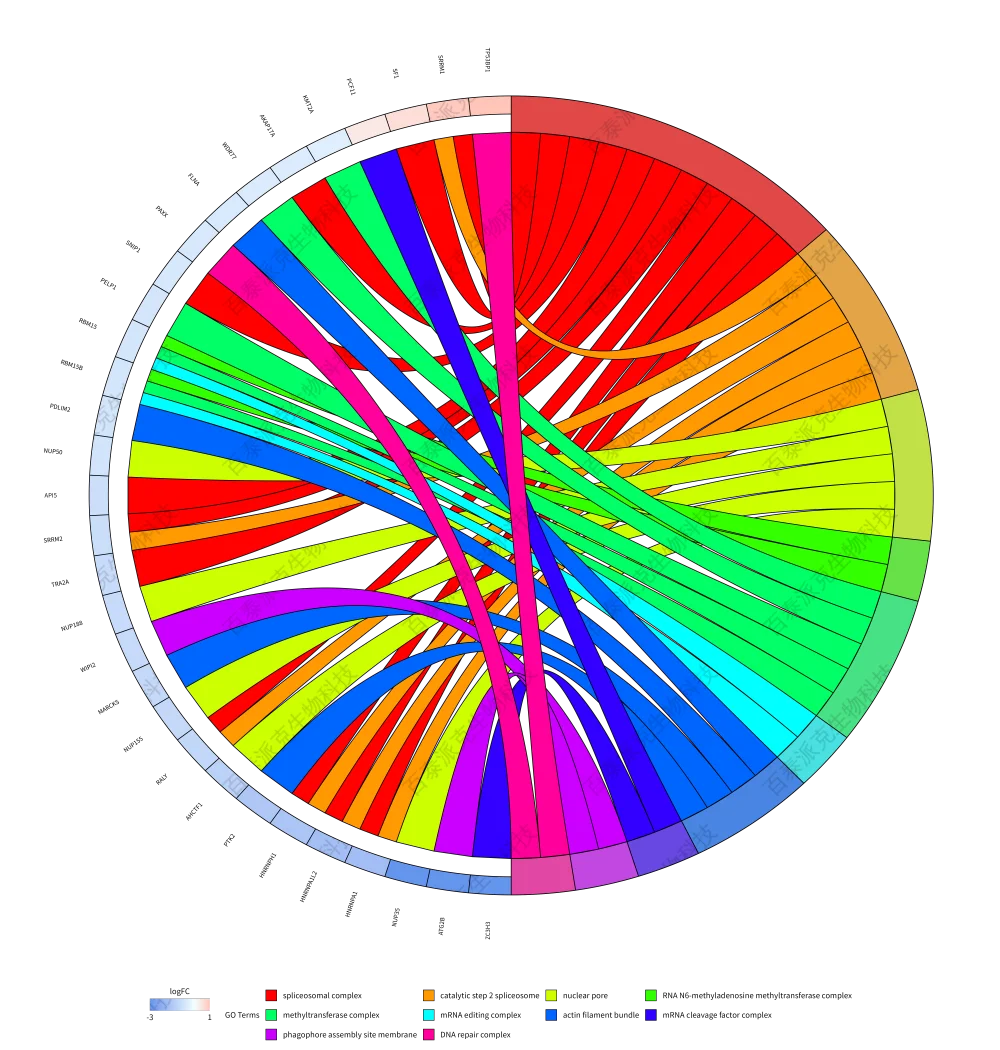
圖16. GO富集弦圖
注:BP、CC、MF按照p_adjust篩選Top10的GO Term(右側);每個GO Term上對應的基因(左側),基因顏色深淺由蛋白的|log2(Fold Change)|決定。
(2)KEGG Pathway富集分析
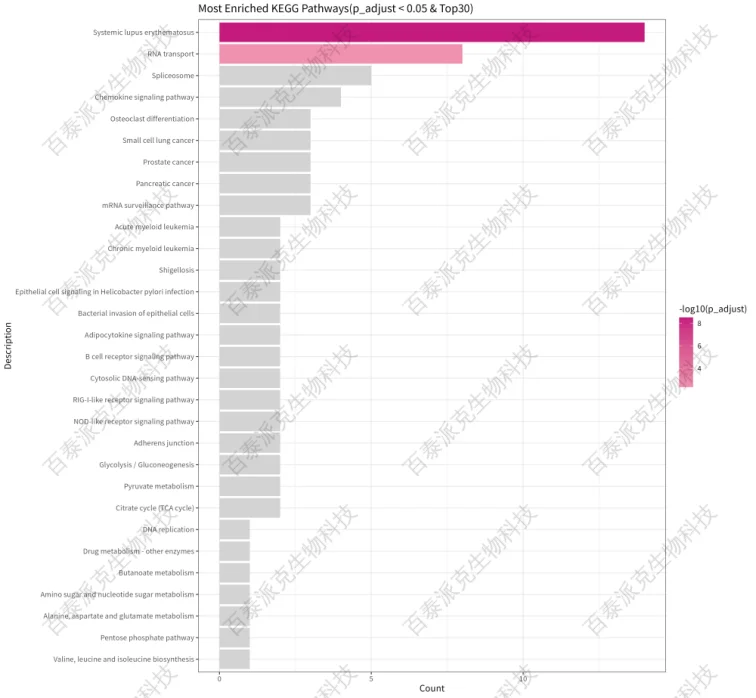
圖17. KEGG Pathway富集柱狀圖
注:橫坐標表示KEGG Pathway上注釋到的基因數目,縱坐標表示按照p_adjust篩選Top30的 KEGG Pathway;顏色深淺表示富集的顯著性大小,越顯著越紅;灰色的柱子表示p_adjust ≥0.05的KEGG Pahtway。
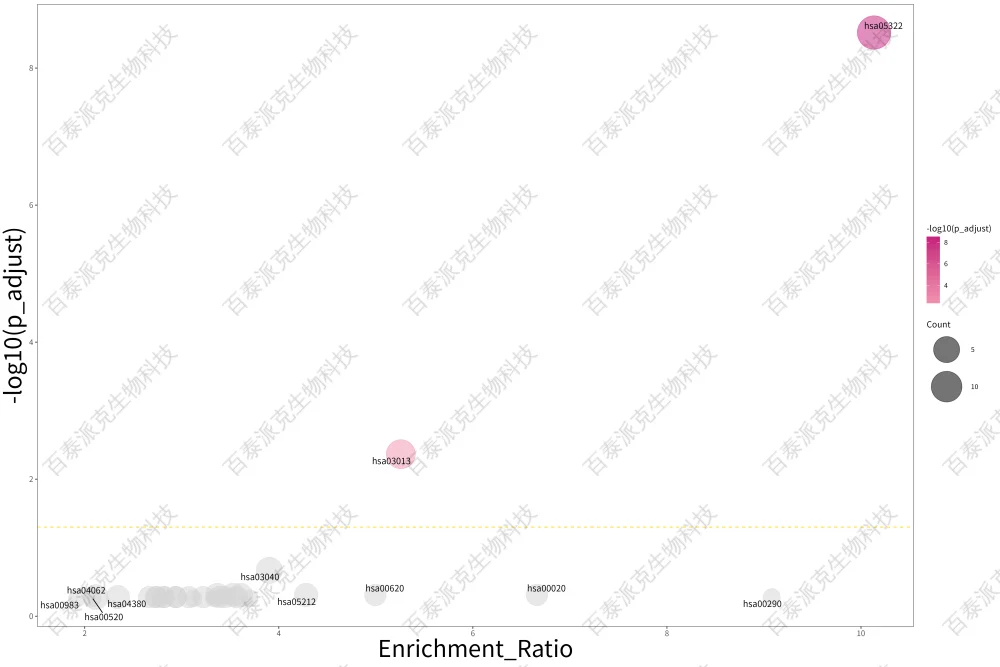
圖18. KEGG富集泡泡圖
注:橫坐標表示KEGG Pathway的Enrichment Ratio,縱坐標表KEGG Pathway的-log10(p_adjust),值越大越顯著;顏色深淺表示富集的顯著性大小,越顯著越紅;橫向黃色虛線以下灰色的圓圈表示p_adjust ≥0.05的KEGG Pahtway。
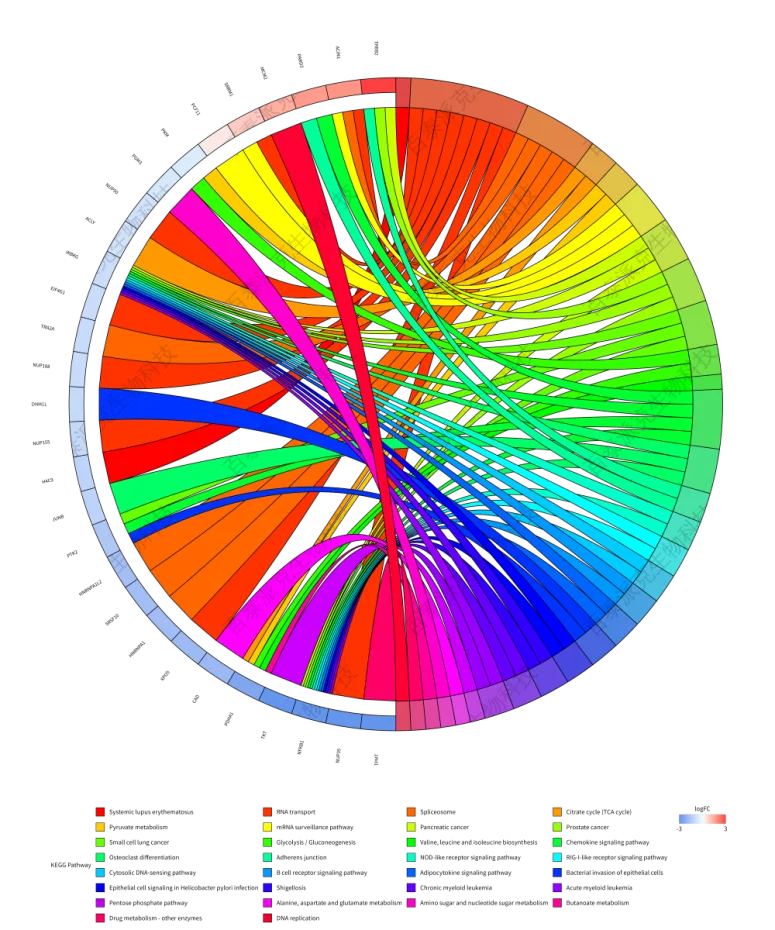
圖19. KEGG富集弦圖
注:按照p_adjust篩選Top30的KEGG Pathway(右側);每個KEGG Pathway上對應的基因(左側),基因顏色深淺由蛋白的|log2(Fold Change)|決定。
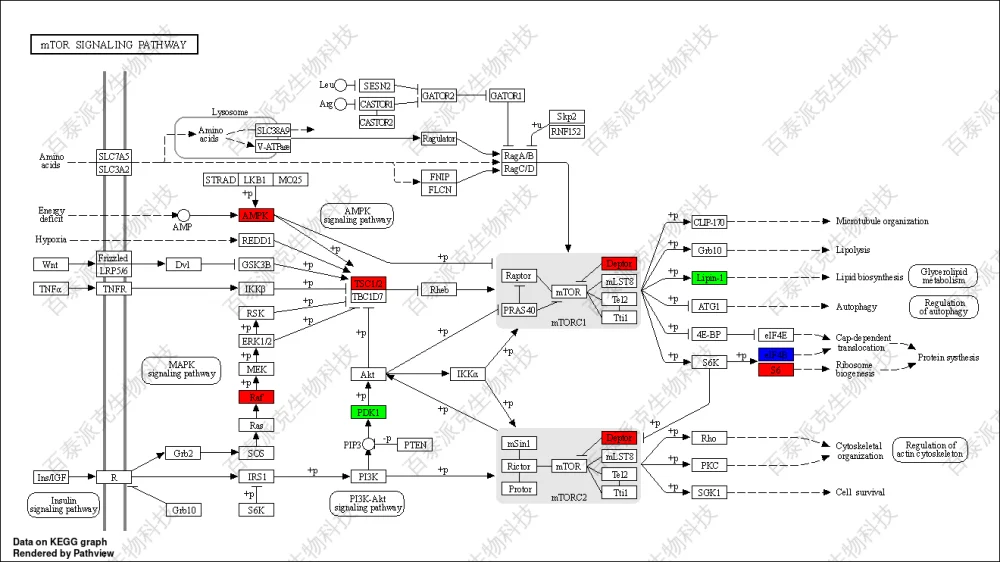
圖20. KEGG通路圖
注:KEGG Pathway通路圖,紅色的點表示基因對應的蛋白都屬于上調表達,綠色表示基因對應的蛋白都屬于下調表達,藍色表示基因對應的蛋白即包含上調表達又包含下調表達。
8、高級分析
(1)細胞類型注釋
單細胞類型注釋是單細胞分析中的一個關鍵步驟,它涉及將每個細胞歸類到特定的細胞類型或細胞狀態。這一過程對于理解細胞異質性、細胞分化路徑和細胞功能至關重要。基于現有的數據庫CellMarker、PanglaoDB等能實現人、小鼠多種組織類型樣本的單細胞類型注釋工作。其中CellMarker數據庫是專門為人和小鼠設計的,包含2w+細胞標志物,2k+細胞類型,幾百種組織,數據來源10w+發表的文獻,并經手動整理和注釋。
我們基于現有數據庫的細胞標志物信息,對項目數據進行分析,可以將每個細胞進行類型注釋,甚至是亞型注釋。
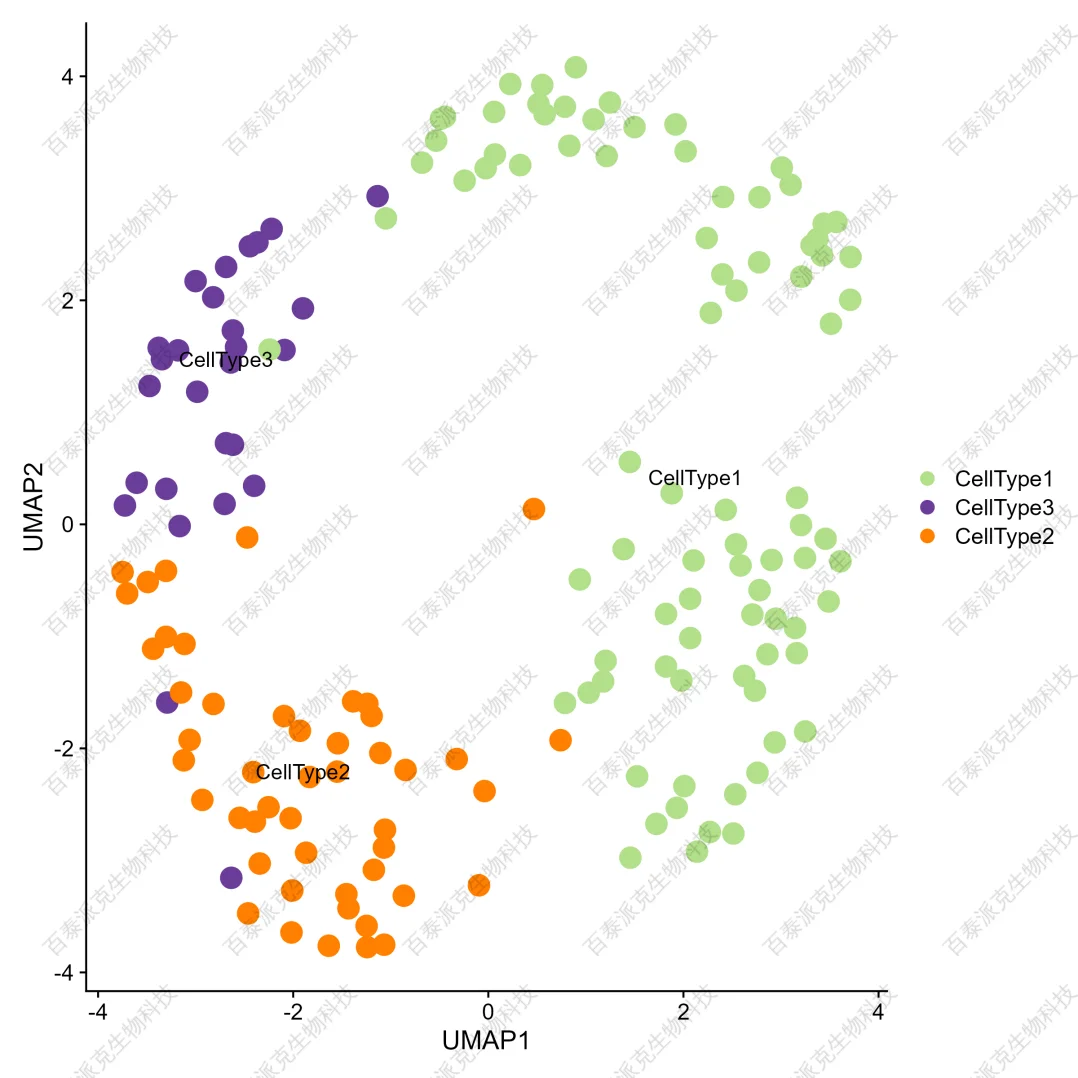
圖21. 細胞注釋分布圖
(2)擬時間分析
單細胞擬時間分析(Pseudotime Analysis)是一種用于理解細胞在分化、生長或變化過程中所經歷的狀態轉換的方法。它通過表達模式對單個細胞進行排序,從而模擬細胞在發育過程中的動態變化的技術,它也被稱為細胞軌跡分析(cell trajectory analysis),主要用于推斷發育過程中細胞的分化軌跡或細胞亞型的演化過程。這種排序技術實際上是一種在低維空間排布高維數據的降維技術。擬時間分析的應用場景擬時間分析在發育相關研究中使用頻率較高,例如,在細胞分化等過程中,細胞并不是完全同步的,通過擬時間分析可以跟蹤同一時間捕獲的細胞間的表達變化,從而了解細胞從一種狀態轉換到另一種狀態時所發生的調節更改的順序。
我們利用monocle對單細胞蛋白數據進行擬時間分析。結果示例如下:
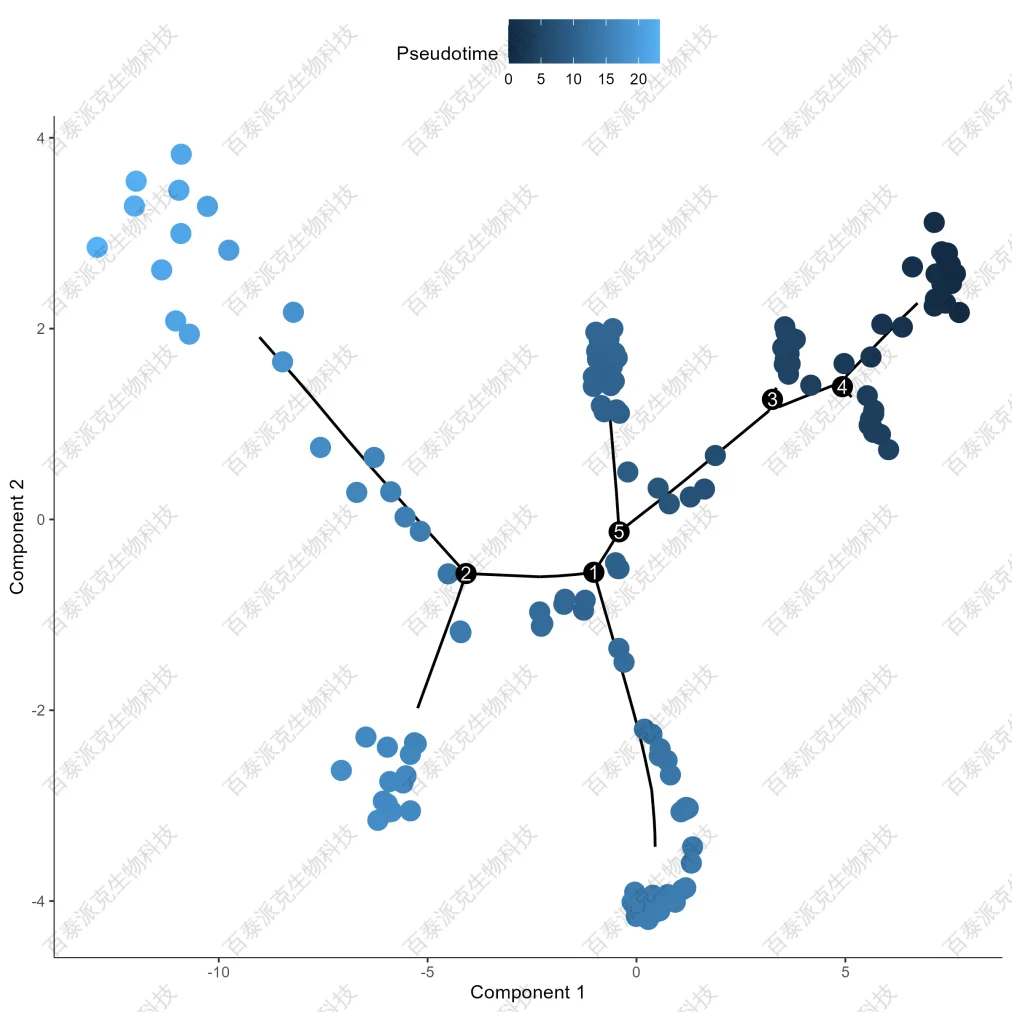
圖22. Pseudotime 軌跡圖
注:顏色深淺表示Pseudotime值(偽時間是一個連續的數值,代表細胞在某一發育軌跡上的相對位置。它不是真實的時間,而是一種反映細胞分化順序的度量),不同分支表示不同演化方向,交叉位置是分支點。
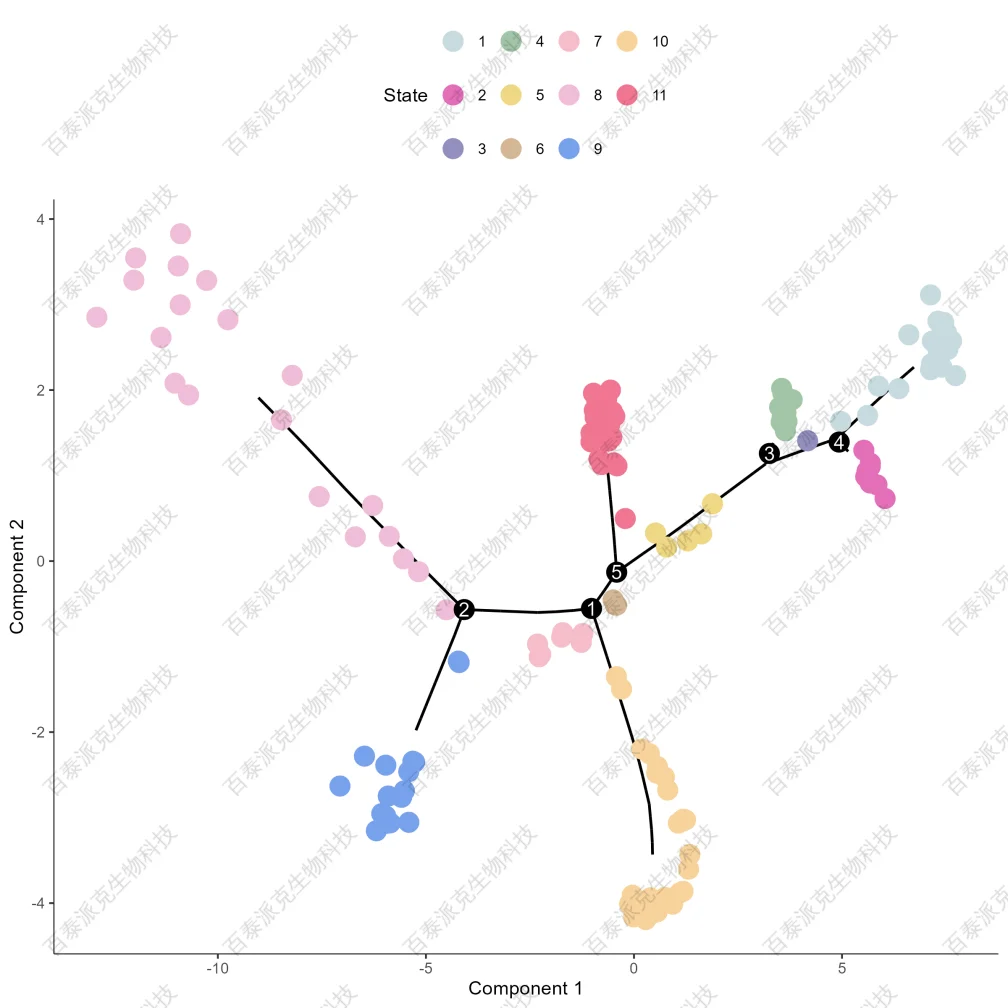
圖23. Pseudotime State分布圖
注:根據Pseudotime分析結果,細胞劃分不同State, 及其在軌跡上的分布。
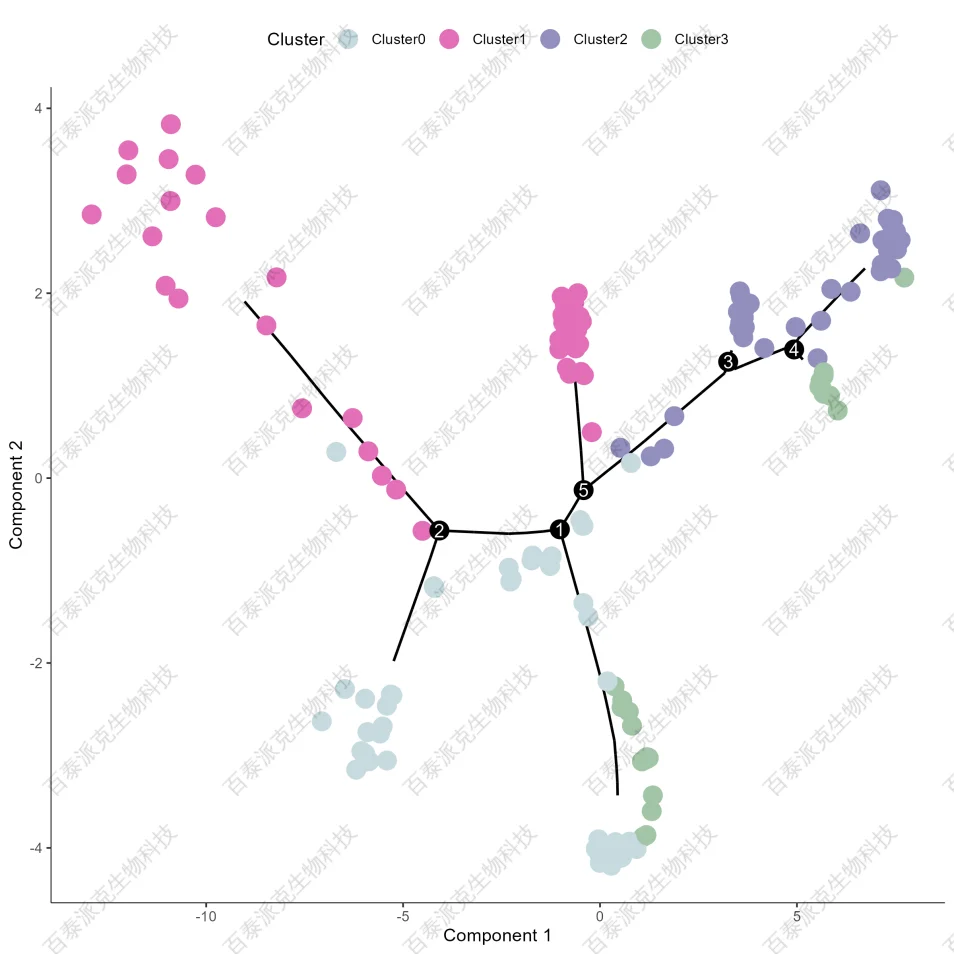
圖24. Pseudotime 分群分布圖
注:根據Pseudotime分析結果,結合單細胞降維分群Cluster,展示Cluster在軌跡上的分布。
單細胞蛋白組技術作為一種高分辨率的分子層面分析工具,不僅突破了傳統蛋白質組學的技術瓶頸,還為揭示細胞異質性、解析細胞微環境以及探索疾病機制提供了前所未有的深度和精度。北京百泰派克生物科技有限公司作為國內領先的蛋白質組學技術服務平臺,提供高質量的單細胞蛋白組檢測服務。我們不僅具備規范化、自動化的樣本處理流程,還在數據分析與生物信息解讀方面積累了豐富的經驗,確保為每位客戶提供專業、精準的科研支持。我們期待與更多科研機構和企業開展深入合作,歡迎聯系我們!
相關服務:
單細胞蛋白質組學分析服務
關于我們
北京百泰派克生物科技有限公司致力于為生物/制藥和醫療器械行業提供質量控制檢測和項目驗證等專業服務。公司實驗室遵循NMPA、ICH、FDA和EMA等的法規和指導原則,通過CNAS/ISO9001雙重質量體系認證,建立了完備的質量體系,數據冷熱/異地備份,設備定期計量/期間核查,軟件審計追蹤,為客戶提供一體化解決方案和技術服務,支持新藥研發、藥物申報注冊和生產放行。
1.公司采用ISO9001質量控制體系,專業提供以質譜為基礎的CRO檢測分析服務;
2.獲國家CNAS實驗室認可,為客戶提供符合全球藥政法規的藥物質量研究服務;
3.業務范圍覆蓋蛋白質組學、多肽組學、代謝組學、生物藥物表征、單細胞分析、單細胞質譜流式、生信云分析以及多組學生物質譜整合分析等;
4.七大質量控制檢測平臺,滿足您一站式服務需求;
5.服務3000+企業,10000+客戶的選擇;
6.致力于為您提供優質的生物質譜分析服務!
技術服務一覽圖
