巧用數據庫 | 我是如何使用NCBI,UCSC,Ensembl,Uniprot四個數據庫的?
我們吉凱基因網上商城(www.taogene.com)中引物產品對應的基因目前已經覆蓋NCBI refseq數據庫、mirbase數據庫、circbase數據庫中human,mouse,rat的所有基因以及Ensembl數據庫的部分基因。
但今天呢,我們不說我們的引物產品,也不談數據之間的差別,就說說這幾個數據庫到底能做什么?
毋庸置疑,NCBI,UCSC,Ensembl,UniProt四個數據庫功能非常強大,下面給大家介紹下我自己用的最多的功能。
NCBI 中BLAST工具
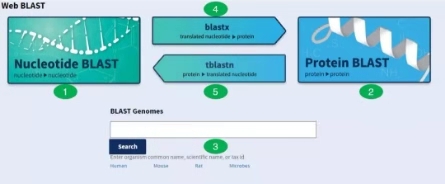
NCBI中的Nucleotide BLAST、Protein BLAST、BLAST Genomes(對應圖中的1、2、3),這三種比對工具用的最多,其余兩種blastx、tblastn(對應圖中的4和5),用的相對較少,但是不得不說,真的好用!!
1.Nucleotide BLAST(BLASTN):nucleotide–nucleotide BLAST,核苷酸與核苷酸比對工具,可以序列之間比對,也可以與NCBI nucleotide database比對;
2.Protein BLAST(BLASTP):protein–protein BLAST,蛋白序列與蛋白序列比對工具。可以序列之間比對,也可以與NCBI Protein database比對;
3.BLAST Genomes:核苷酸與選擇的基因組之間的比對;
4.blastx:核苷酸與蛋白序列比對,將給定的核酸序列按照六種閱讀框架將其翻譯成蛋白質與蛋白質數據庫中的序列進行比對,對分析新序列和EST很有用;
5.tblastn:將給定的氨基酸序列與核酸數據庫中的序列(雙鏈)按不同的閱讀框進行比對,對于尋找數據庫中序列沒有標注的新編碼區很有用;
這五種比對工具相信大家都用過,那么比對結果怎么看呢?以tblastn舉例。比對結果中需要注意Query Coverage和Identities兩個數值,只有將兩個數值結合起來看,才能很好地說明序列的比對情況。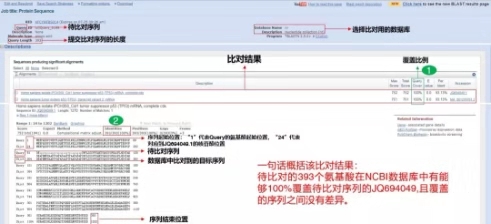
1.Query Coverage:對應圖中的1,數值越高,代表與之匹配的序列越長;
2.Identities:對應圖中的2,數值越大,代表與之同源性越高。
再舉例一個概念:low-complexity sequence。顧名思義,就是序列復雜度低,比如連續的T,或者相對有規律的序列。這種序列在設計引物(比如qPCR引物)的時候盡量避開,原因是引物如果落在這些位置,容易導致引物的非特異性結合,帶來的可能結果就是非特異性產物的產生。
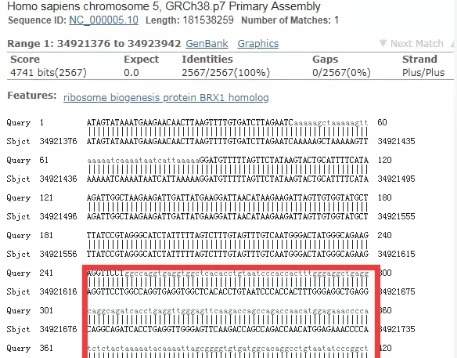
那如何從比對結果中確定哪部分序列是low-complexity sequence呢?如下圖,比對結果中小寫的、灰色的堿基序列就是low-complexity sequence。
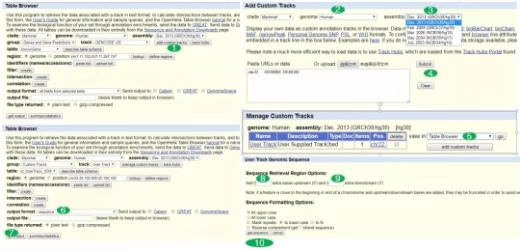
UCSC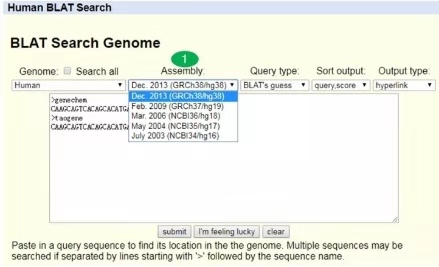
2. Table Browser可以很方便地根據基因的起始位置和終止位置獲得對應的序列,同樣可以選擇不同的assembly。
Ensembl
TargetScan是最常用的microRNA與靶基因結合位點預測網站,該網站用的靶基因UTR數據庫即Ensembl。
如下圖,預測結果中給出了ENSMUST00000103114.2。首先從這個transcript可以看出,基因物種為mouse,帶有version信息“.2”。由于Ensembl數據庫信息是定期更新的,會有不同的release。即有可能ENSMUST00000103114.2 version的信息在數據庫當前的release(Current Ensembl release 97)中并不存在,ENSMUST00000103114目前在Ensembl release 97中是ENSMUST00000103114.7 version。
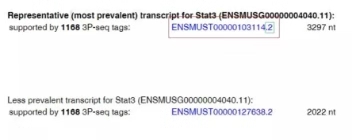
Current Ensembl release 97中ENSMUST00000103114的信息如下:
不同的release里邊的序列可能會有不同,那如何找到ENSMUST00000103114.2對應的序列呢?進入到不同的release里邊去找ENSMUST00000103114.2。
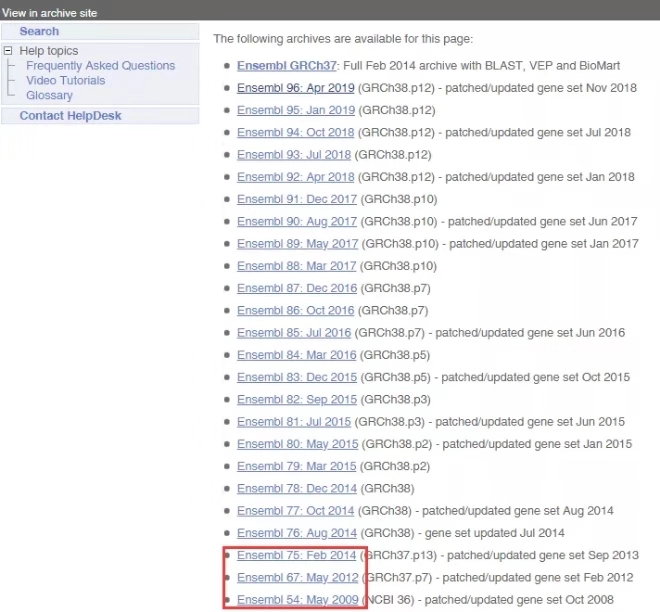
心明眼亮的你們可能注意到了一個問題,為什么沒有release 66?Ensembl并不會把所有的release展示出來,那如果現有的release里邊都沒有ENSMUST00000103114.2,要去哪里找呢?去FTP下載(ftp://ftp.ensembl.org/pub/)即可。
UniProt
UniProt(Universal Protein Resource)是全球有關蛋白質方面信息最全面的資源庫。UniProt提供了完全分類的、有豐富且準確注釋信息的基于知識的蛋白質序列信息,數據庫可以提供的信息包括蛋白功能描述、GO條目、細胞定位、組織特異性表達情況、生理病理情況描述、互作蛋白、Domain、翻譯后修飾位點等信息。蛋白的信息描述段落均會標出引用文章,并且可以跳轉到PubMed界面進行瀏覽。
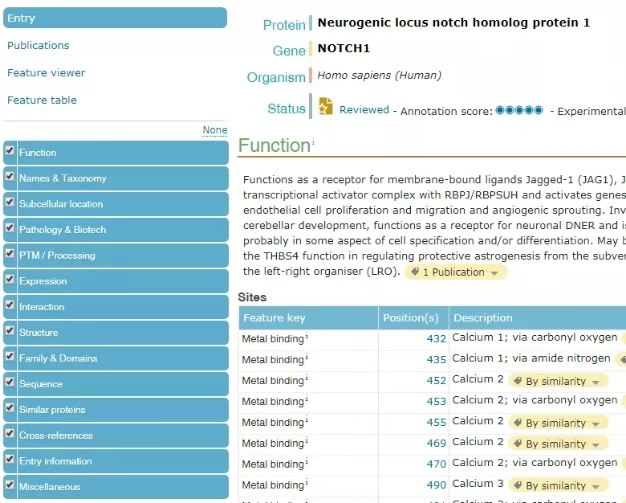
1.Function 板塊可以看到基因的功能以及參與的生物學過程;
2.Names & Taxonomy板塊可以看到基因的細胞定位以及拓撲結構域,比如NOTCH1在該板塊能夠看到胞外段,胞內段信息;
3.PTM / Processing板塊描述了蛋白的翻譯后修飾情況;
4.Structure板塊可以看到蛋白的三維空間結構;
5.Sequence板塊可以得到一個'canonical'序列信息,在不知道選擇哪個轉錄本做研究室可以參考該信息判斷。