蛋白質(zhì)組學(xué)可以克服核酸水平預(yù)測的不確定性、反映核酸翻譯后修飾情況。
01.常用技術(shù)
1. 非靶向蛋白組學(xué)
1.1 蛋白質(zhì)定性(膠條鑒定和溶液鑒定)
1.2 高通量定量蛋白組(Label free、 iTRAQ/TMT 和 DIA 定量)
1.3 多肽組學(xué)
2. 靶向蛋白組(PRM 靶向蛋白/肽段定量)
3. 修飾蛋白組學(xué)(定量磷酸化修飾組學(xué)、定量糖基化修飾蛋白組學(xué)、定量乙酰化修飾蛋白組學(xué)和定量泛素化修飾蛋白組學(xué))
4. 互作蛋白組學(xué)(代謝物與蛋白互作研究)
02.儀器平臺

03.蛋白序列數(shù)據(jù)庫
最常用 Uniport 數(shù)據(jù)庫,第二優(yōu)先級是 GeneBank/NCBI 數(shù)據(jù)庫,最次選擇 RNA sequence 序列信息進行氨基酸轉(zhuǎn)換。
04.搜索軟件
Proteome Discovery、Mascot、SEQUST、MaxQuant
05.基本流程
最常用 Uniport 數(shù)據(jù)庫,第二優(yōu)先級是 GeneBank/NCBI 數(shù)據(jù)庫,最次選擇 RNA sequence 序列信息進行氨基酸轉(zhuǎn)換。
04.搜索軟件
Proteome Discovery、Mascot、SEQUST、MaxQuant
05.基本流程

06.分析結(jié)果展示
1. 基礎(chǔ)分析
數(shù)據(jù)預(yù)處理
差異表達蛋白篩選
2. 常規(guī)數(shù)據(jù)分析
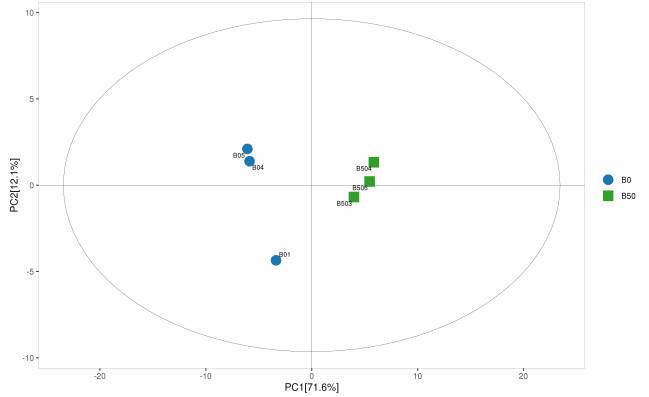
主成分分析
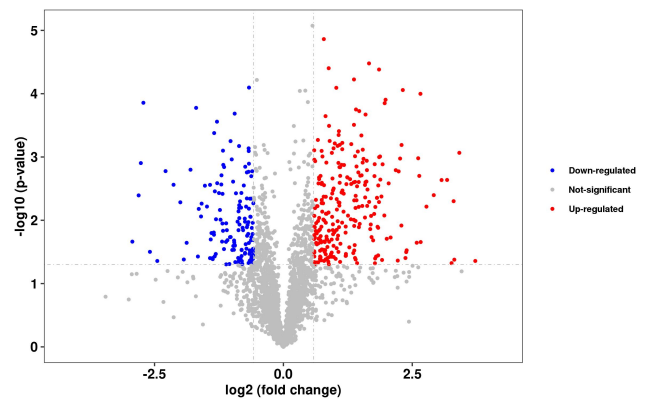
火山圖分析
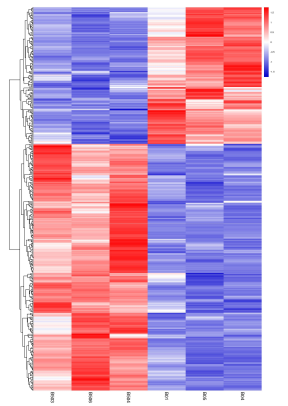
層次聚類分析
3.功能分析
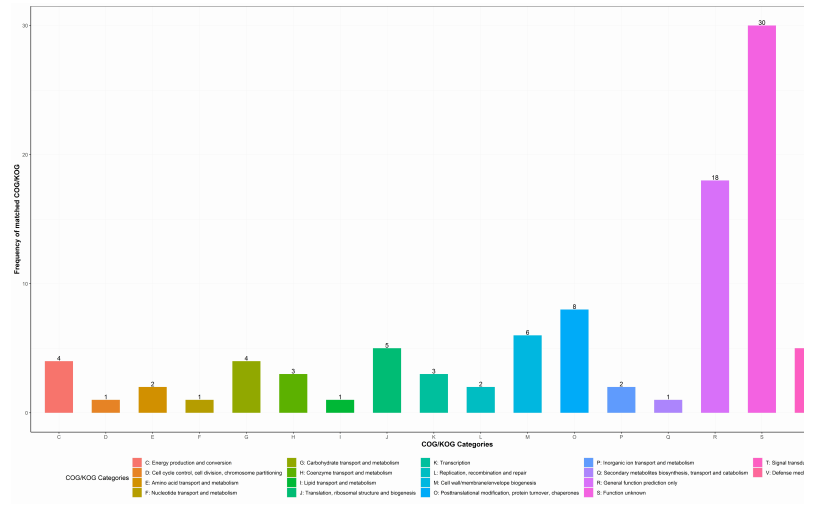
COG 注釋分析
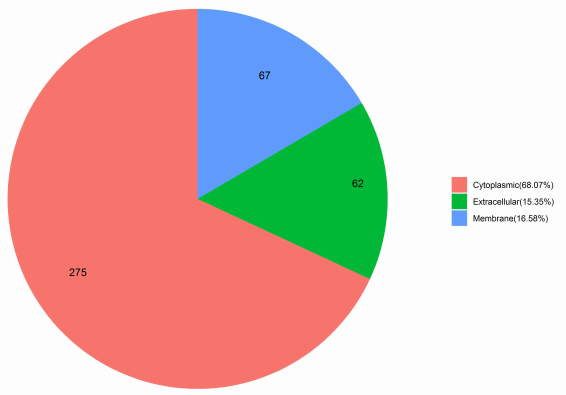
亞細胞定位分析
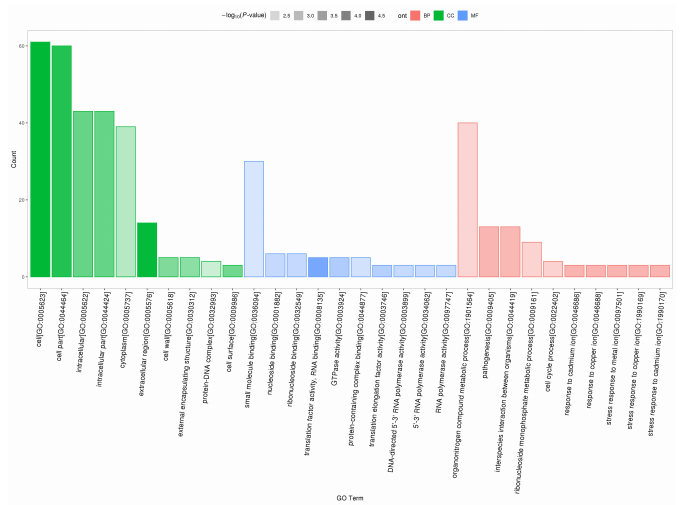
GO 注釋富集分析
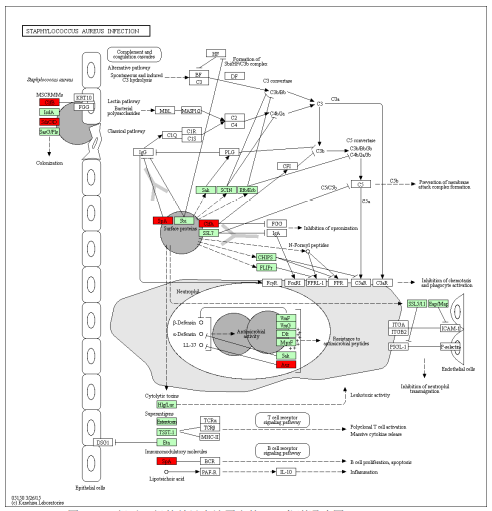
KEGG 注釋富集分析
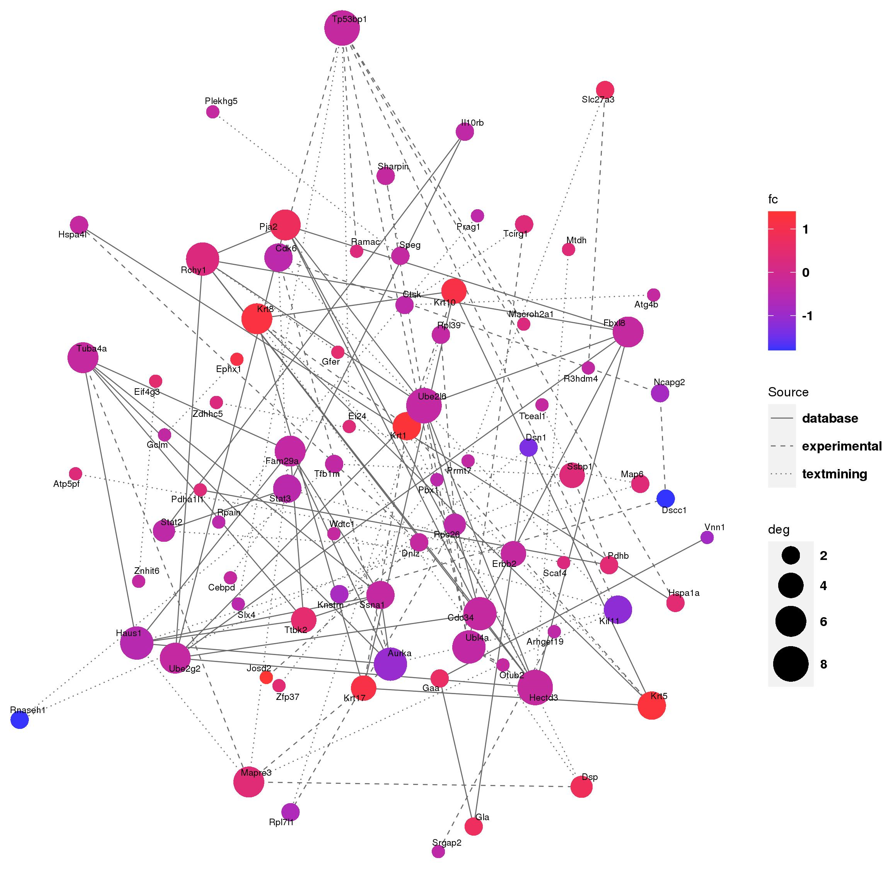
PPI 網(wǎng)絡(luò)構(gòu)建分析
4.修飾蛋白特有分析
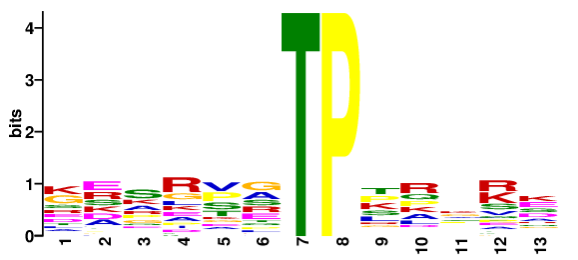
Motif 分析
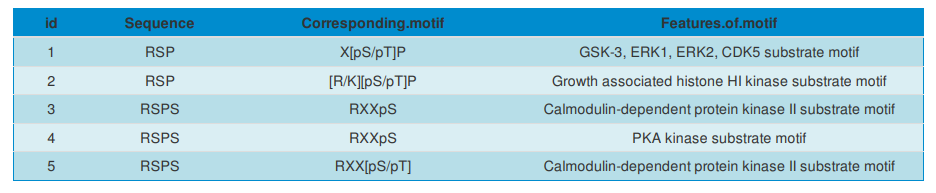
激酶(kinase)預(yù)測分析